
词嵌入(Embedding)

词嵌入(Embedding)
可爱可倾词嵌入(Embedding)
1 位置编码(Positional Encoding)
位置编码是Transformer模型中的一部分,用于为输入序列中的每个位置提供一个位置向量,提供时序信息。
1.1 标准位置编码
如果输入序列长度为seq_len,词嵌入的维度为d_model。位置编码的计算公式如下:
\[ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)\\ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) \]
其中,\(pos\)表示token在序列中的位置,\(i\)表示维度。位置编码的维度与词嵌入的维度相同。
偶数维度用sin函数编码,奇数维度用cos函数编码。
对于一个序列,位置编码的维度为[seq_len, d_model]。
词嵌入和位置编码相加,作为模型的输入。
比如对于其中一个token,就是一个[d_model]的一维向量,对位相加一个[d_model]的一维位置编码向量。
1.2 旋转位置编码(ROPE)
ROPE(Rotary Position Embedding)通过对词向量进行旋转变换来编码位置信息,而不是像传统方法那样将位置编码直接加到词向量上。
如果输入序列长度为seq_len,词嵌入的维度为d_model。RoPE的计算公式如下:
- 复数形式 \[ \text{RoPE}(x_m, m) = x_m \cdot e^{im\theta} \]
- 基本形式 \[ \theta_{pos,i} = \frac{pos}{10000^{\frac{2i}{d}}}\\ \text{RoPE}(x, pos)_{2i} = x_{2i} \cos(\theta_{pos,i}) + x_{2i+1} \sin(\theta_{pos,i})\\ \text{RoPE}(x, pos)_{2i+1} = x_{2i+1} \cos(\theta_{pos,i}) - x_{2i} \sin(\theta_{pos,i}) \]
- 矩阵形式 \[ R_{\theta,pos,2i} = \begin{bmatrix} \cos(\theta_{pos,i}) & -\sin(\theta_{pos,i}) \\ \sin(\theta_{pos,i}) & \cos(\theta_{pos,i}) \end{bmatrix}\\ \begin{bmatrix} x'_{2i} \\ x'_{2i+1} \end{bmatrix} = \begin{bmatrix} x_{2i} \\ x_{2i+1} \end{bmatrix} \cdot R_{\theta,pos,2i} \]
1.3 线性注意力偏置(ALiBi)
不同于传统方法,ALiBi不直接修改token embeddings,而是在注意力计算过程中添加一个线性偏置项,这个偏置项随着序列中tokens的相对距离线性增加。
[(Q, K, V) = ( + B) V]
其中,位置偏置矩阵 ( B ) 定义为:
[B_{ij} = -|i - j| m]
2 词向量(Word2Vec)
上下文相似的两个词,它们的词向量也应该相似,比如香蕉和梨在句子中可能经常出现在相同的上下文中,因此这两个词的表示向量应该就比较相似。
Word2Vec是一种词嵌入技术,它的目的是将词语映射到一个低维空间中,使得语义相近的词在这个空间中的距离也比较近。核心思想是通过训练神经网络,使得词向量的内积尽可能的大,而与之不相关的词向量的内积尽可能的小。
Word2Vec模型有两种:
- CBOW: 通过上下文预测中心词,即用\(w_{t-1}, w_{t-2}, w_{t+1}, w_{t+2}\)预测\(w_t\)
- Skip-gram: 通过中心词预测上下文,即用\(w_t\)预测\(w_{t-1}, w_{t-2}, w_{t+1}, w_{t+2}\)
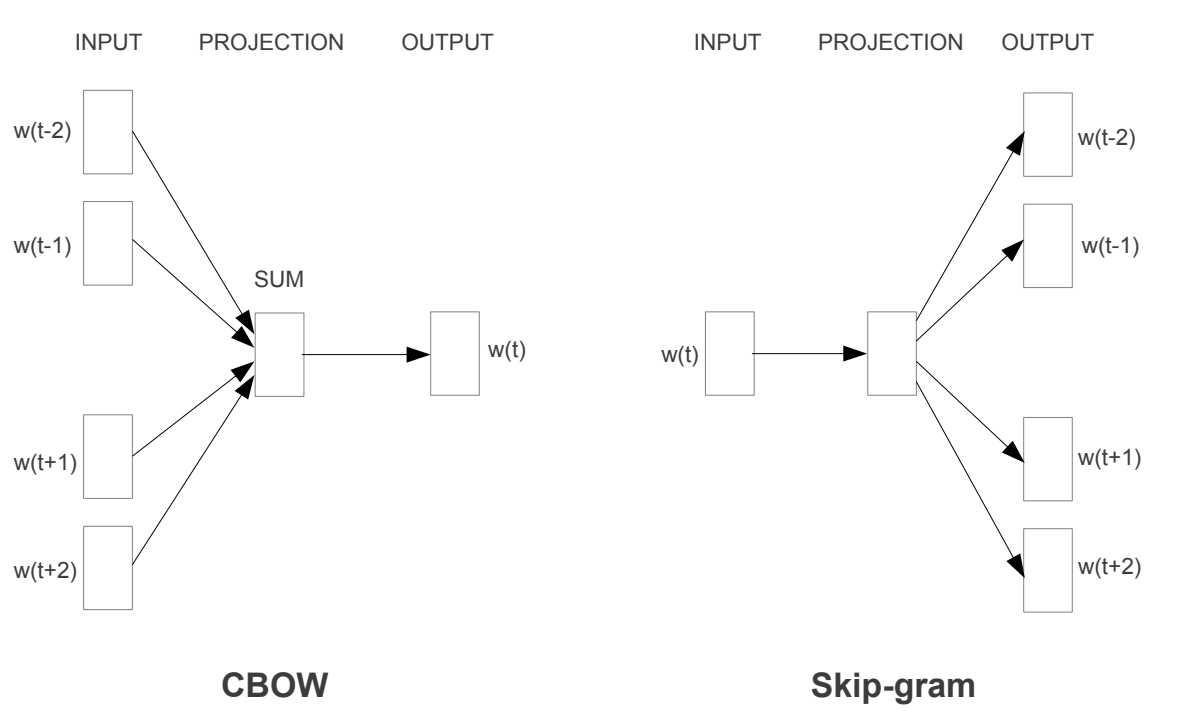 图1:Word2Vec
图1:Word2Vec







