
注意力机制(Attention)

注意力机制(Attention)
可爱可倾注意力机制
1 Self-Attention
Self-Attention 是一种注意力机制,它允许模型在输入序列中的不同位置之间建立依赖关系。
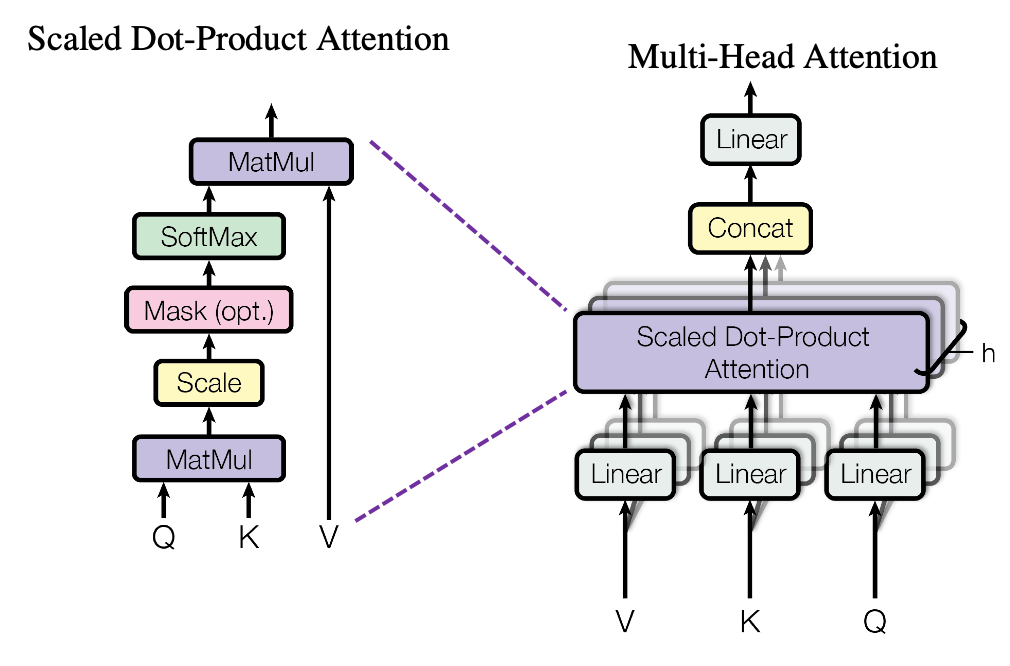 图1:Self-Attention and Multi-Head Attention
图1:Self-Attention and Multi-Head Attention
Self-Attention 机制的计算如下:
\[ \text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}} + \text{mask})V \]
2 Multi-Head Attention
多头注意力相比单一的自注意力,通过并行计算多个头的注意力分数,能够从多个子空间中提取信息,捕捉到更加丰富和复杂的特征,极大地提高了模型的表达能力和鲁棒性。
2.1 MHA变种
为了加快注意力计算速度,通常会采用KV-Cache,但是随着上下文窗口或批量大小的增加,多头注意力 (MHA)模型中与 KV 缓存大小相关的内存成本显著增长
对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,而不会大幅降低性能,可以使用
- 具有单个 KV 投影的多查询注意(MQA):只使用一个键值头,虽大大加快了解码器推断的速度,但MQA可能导致质量下降
- 具有多个 KV 投影的分组查询注意力(GQA):通过折中(多于一个且少于查询头的数量,比如4个)键值头的数量,使得经过训练的GQA以与MQA相当的速度达到接近多头注意力的质量
GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均优于 MQA 变体
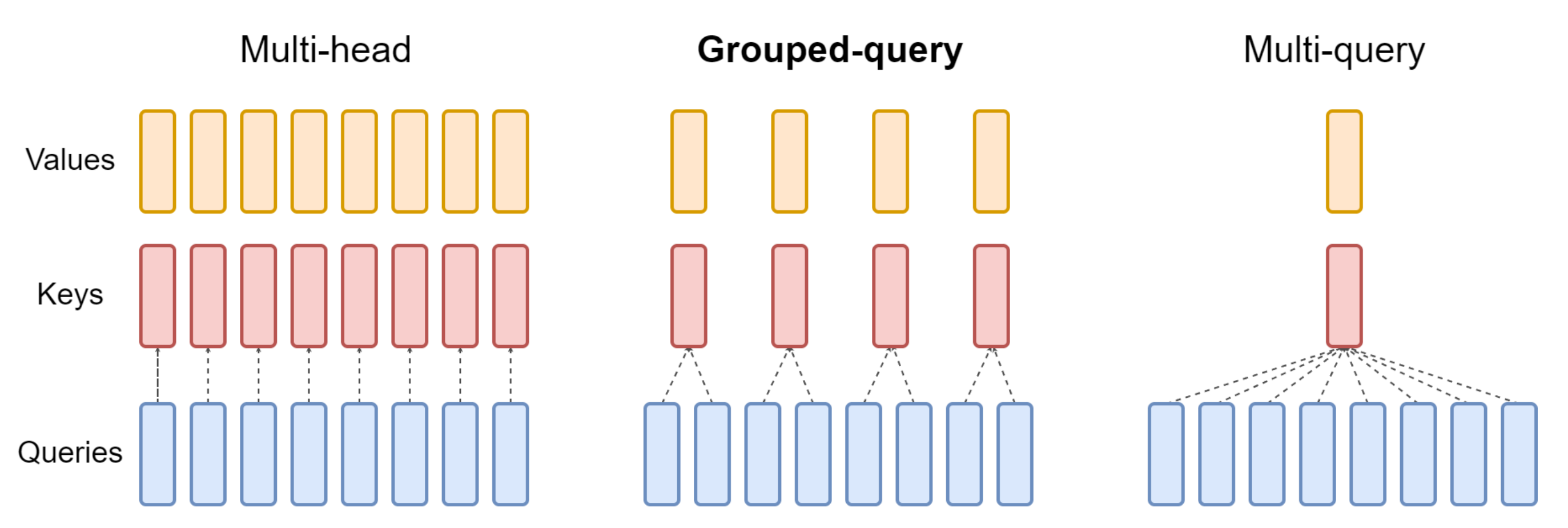 图1:MHA_GQA_MQA
图1:MHA_GQA_MQA
2.2 GQA
GQA的分组数是一个超参数,组数越大越接近MHA,推理延迟越大,同时模型精度也越高(原论文中当组数量从1逐渐上升到8时,模型推理的开销并没有明显的增长,在8以后推理开销显著变大)。MQA略微损失了模型精度,但是确实能够大幅降低推理开销,而如果选择了合适的分组数,GQA能够两者皆得。
在理论层,MQA和GQA对推理的帮助主要是以下两点
- 降低内存读取模型权重的时间开销:由于Key矩阵和Value矩阵数量变少了,因此权重参数量也减少了,需要读取到内存的数量量少了,因此减少了读取权重的等待时间
- KV-Cache空间占用降低:KV-Cache需要存储的参数量降低了head_num倍,从而提高KV-Cache的读写效率;另一方面,可以有空间来增大batch_size,从而提高模型推理的吞吐量
注意MQA和GQA并没有降低Attention的计算量(FLOPs),因为Key、Value映射矩阵会以广播变量的形式拓展到和MHA和一样,因此计算量不变,只是Key、Value参数共享。
2.3 MQA
MQA 让所有的头之间 共享 同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。但是,MQA 会导致模型性能和表达能力下降。
3 Cross-Attention
Cross-Attention 是一种注意力机制,它允许模型在不同序列之间建立依赖关系。它的查询(Query)来自解码器,而键(Key)和值(Value)来自编码器。这种机制允许解码器在生成输出时,参考编码器处理后的输入信息。除此之外和 Self-Attention 机制类似。
4 其他
- mask取全1就对应双向注意力,mask取下三角矩阵就对应单向注意力







