
LLM模型之T-MAC

LLM模型之T-MAC
可爱可倾T-MAC
CPU上通过查找表进行低比特量化大模型部署 原文链接:CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge GitHub链接:T-MAC
问题提出
权重量化对于减少 LLM 在设备上的内存占用至关重要。然而,低位 LLM 需要在推理过程中进行低精度权重和高精度激活的混合精度矩阵乘法 (mpGEMM)。现有系统缺乏对 mpGEMM 的原生支持,只能通过去量化权重来实现高精度计算。这种间接的方式可能会导致显着的推理开销。
解决方案
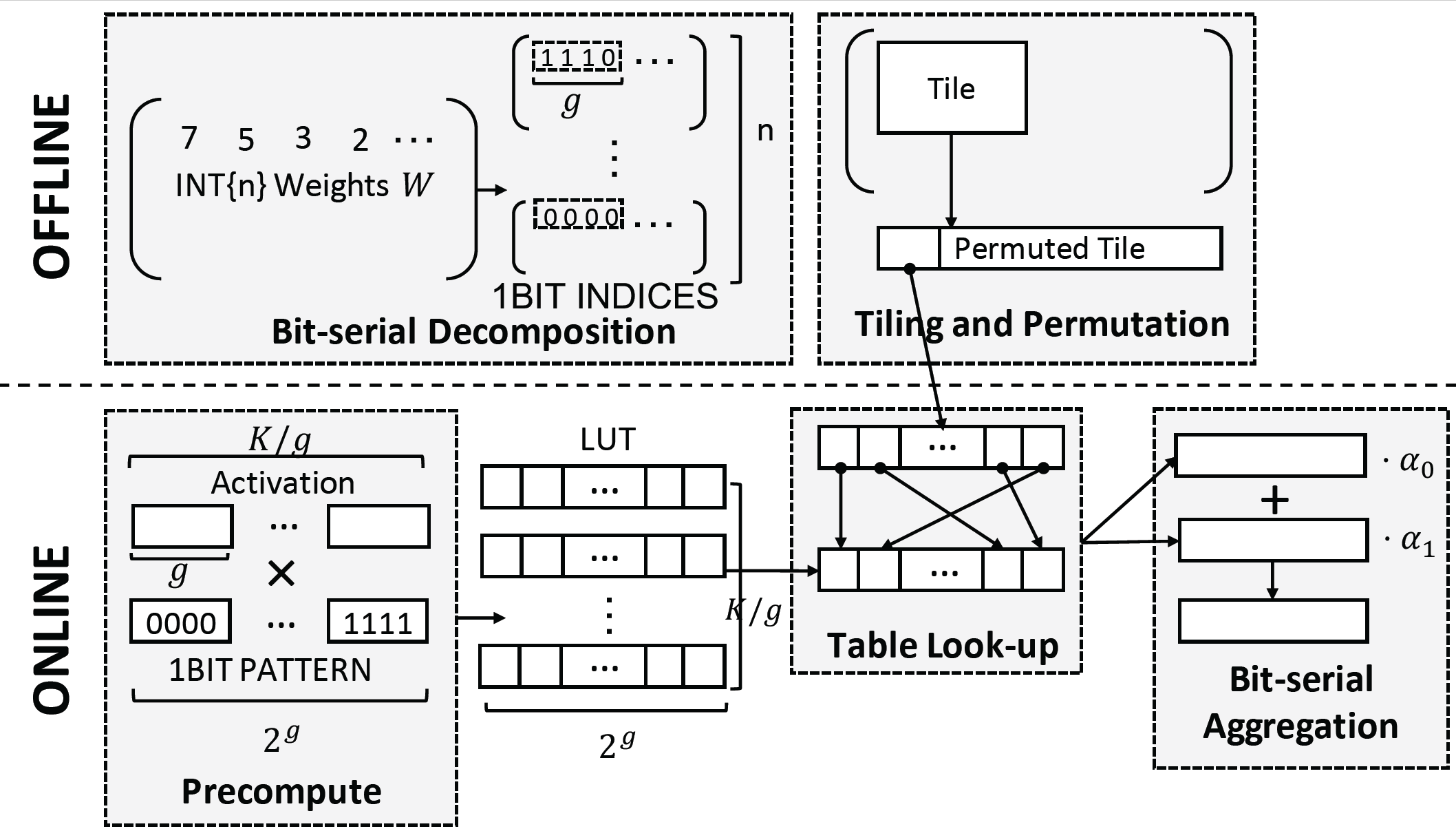 图1: T-MAC Overview
图1: T-MAC Overview
T-MAC简介
一种基于查找表 (LUT) 的方法,将传统的以数据类型为中心的乘法转换为按位表查找,专为 CPU 上的高效低位 LLM(即权重量化 LLM)推理而设计。
直接支持 mpGEMM,无需反量化,简化为查表+加法操作
 图2: T-MAC vs general practice for mpGEMM
图2: T-MAC vs general practice for mpGEMM
两个数的乘法可以转化为一个数乘以另一个数的每一位,然后移位并相加部分积。激活矩阵和权重矩阵之间的 mpGEMM 被分解为激活矩阵和一位矩阵之间的 mpGEMM 的一系列(=权重的位宽),然后将部分结果相加。因此,该方法可以支持激活和权重的任何位宽组合。
\[ \begin{equation} A\times W=A\times(\sum^{n-1}_{i=0}2^i W_i)=\sum^{n-1}_{i=0}2^i A\times W_i \end{equation} \]
对于混合精度 GEMM,𝐴 和 𝑊 分别是激活矩阵和权重矩阵。𝑛 是权重的位宽。 𝑊𝑖 是 𝑊 的每一位矩阵。
原理
按位布局和乘法
整个计算的流程大概如下:
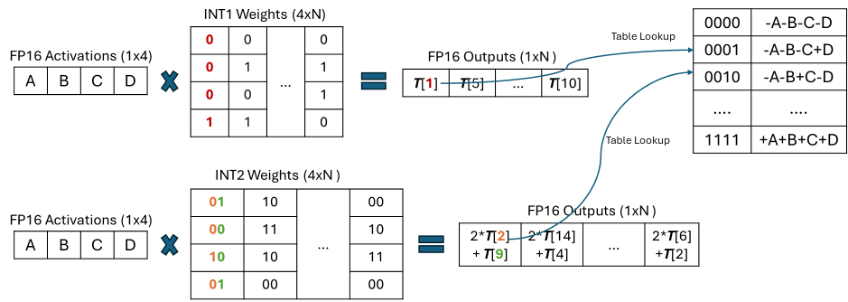 图3: LUT example for mpGEMM
图3: LUT example for mpGEMM
离线准备阶段
在离线准备阶段,n-bit权重矩阵被分解为n个1-bit矩阵。由于1-bit只能代表两个值,对于具有𝑔-bit的组,可能的排列只有\(2^𝑔\)。表大小为\([1, 2^𝑔]\)。
在这里,表的大小是根据权重的行数来确定的,与权重的位宽无关。例如,对于一个8-bit且g行的权重矩阵,会分为8个一样的1-bit矩阵,矩阵的大小为\([1, 2^g]\)。
在线阶段
对于在线阶段,给定 GEMM 的输入激活,T-MAC 构建一个表。在 LUT 期间,一位权重矩阵的每个索引用于查找部分结果的表。部分结果的累加将是最终的GEMM结果。
和右边表的对应关系如下:
- 左边是0001的时候,需要计算
D的值 - 左边是0011的时候,需要计算
C + D的值
表中的-代表舍弃的值,因为这些值在计算中不会被用到。
挑战
- 随机数据访问。有必要将表存放在快速on-chip memory中以降低访问成本。
- 需要更多on-chip memory。查找表需要保存激活向量与所有可能的位模式相乘的中间结果以组合为真正的结果。
以 LUT 为中心的数据布局
- 将查找表放在on-chip memory上 利用 CPU 上的查表向量指令 (TBL/PSHUF) 提升随机访存性能
- 改变矩阵 axis 计算顺序,以尽可能提升放入片上内存的有限 LUT 的数据重用率。
- 为查表单独设计最优矩阵分块 (Tiling) 方式
表压缩方法
- 镜像整合。 LLM 推理的查找表上下文中表值固有的对称属性提供了独特的优化机会。表中的每个正值自然地与其对应的负值配对,反映零值上的镜像。
- 表量化。表量化的运行原理类似于权重和激活量化,旨在降低表值的精度以提高计算效率。例如:最初在查找表中以 16 位浮点 (fp16) 表示的值可以通过缩放因子量化为 8 位整数 (int8)。
实验宣称:表压缩对模型的推理精度的影响可以忽略不计,但是可以显著提高推理性能。
 图4: 镜像合并使表长度减半;表量化减少了表宽度
图4: 镜像合并使表长度减半;表量化减少了表宽度
评估
精度损失
T-MAC 为模型推理引入的误差可以忽略不计,同时提供显着的加速。快速聚合(FA)可以进一步提高性能,但代价是模型质量。
1. 相对于未量化(𝑊𝐹𝑃16𝐴𝐹𝑃16)GEMV内核的归一化均方误差NMSE
| \(\textbf{MxKxN}\) | \(\textbf{llama.cpp}\) | \(\textbf{T-MAC}\) | \(\textbf{T-MAC(+FA)}\) |
|---|---|---|---|
| 4096x4096x1 | 3.33e-03 | 3.35e-03 | 8.09e-03 |
| 11008x4096x1 | 3.44e-03 | 3.46e-03 | 8.27e-03 |
| 4096x11008x1 | 4.13e-03 | 4.15e-03 | 8.45e-03 |
2. WikiText-2 和 ambada_openai 的困惑度,WinoGrande 的问答准确性
| \(\textbf{Framework}\) | \(\textbf{Throughput}\) \(Tokens/sec \uparrow\) |
\(\textbf{WikiText2}\) \(PPL\downarrow\) |
\(\textbf{lambada\_openai}\) \(PPL\downarrow\) |
\(\textbf{WinoGrande}\) \(Acc.\uparrow\) |
|---|---|---|---|---|
| Un-quantized | 3.79 | 5.80 | 12.65 | 71.0 |
| llama.cpp | 5.65 | 5.96 | 12.95 | 70.8 |
| T-MAC | 7.34 | 5.96 | 12.95 | 70.8 |
| T-MAC (+FA) | 8.97 | 6.38 | 13.99 | 67.8 |
性能对比
在GPU上使用查找表尽管理论上计算复杂度降低了,但实际的内核性能比基于反量化的内核要差。这可能归因于 GPU 固定架构的限制,该架构为查找表提供的存储容量不足或表访问速度不够快。
因此本文探索了 CPU 上的查找表内核。
1. 逐步应用 T-MAC 优化
通过逐步应用 T-MAC 优化,Llama-2-7B/13B GEMV 内核在 M2-Ultra 上的多线程性能如下图所示:
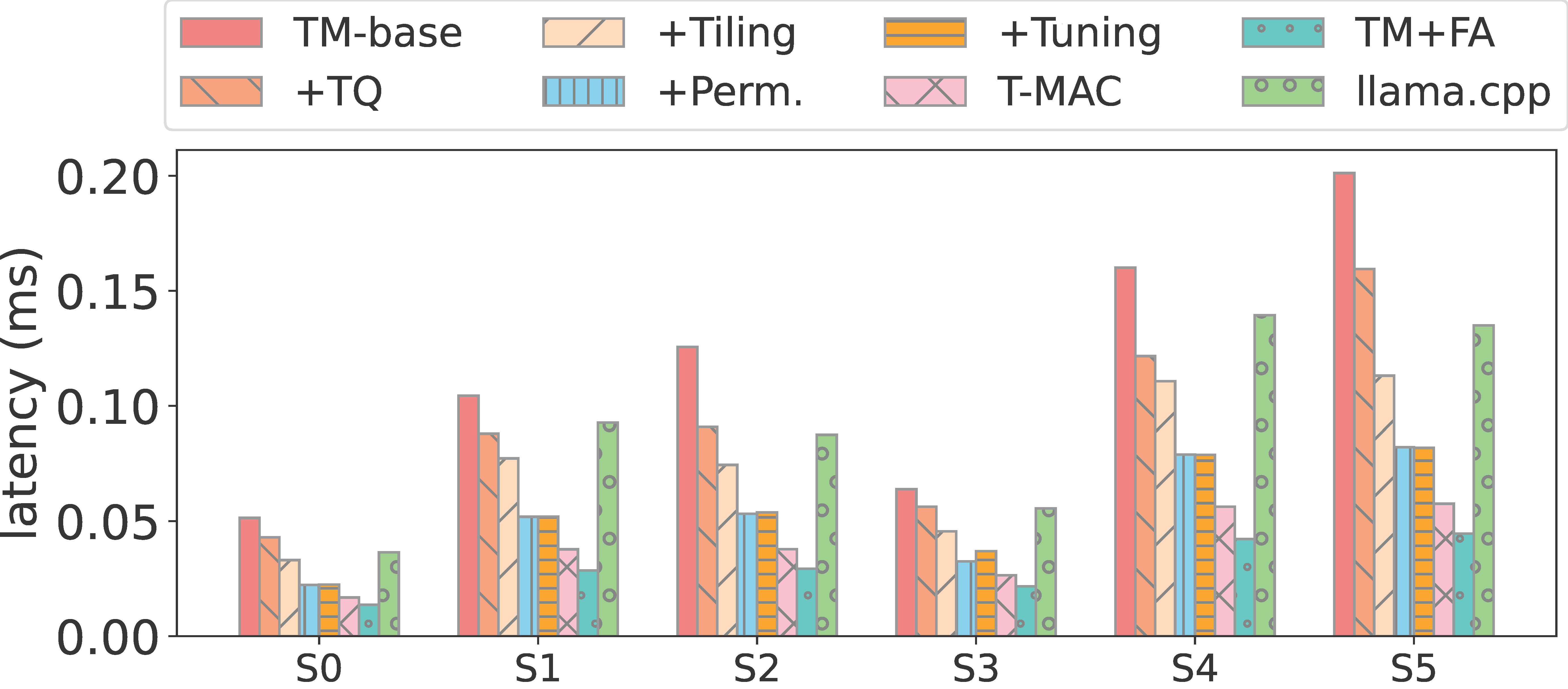 图5: 性能对比
图5: 性能对比
S0-S5:不同的矩阵形状,TM:T-MAC,TQ:表量化,Perm.:排列,IL:交织,FA:快速聚合。
2. 和骁龙 X-ELite NPU芯片的性能对比
X-ELite NPU 只能生成 10.4 个 token/sec,而使用 T-MAC 的 CPU 在两核的情况下就能达到 12.6 个 token/sec,甚至最高能达到 22 个 token/sec。考虑到 T-MAC 的计算性能能随着位数的减少而线性提升(这在基于反量化的 GPU 和 NPU 上是观察不到的),T-MAC 甚至可以在 2 个 bit 下匹敌单核 CPU 的 NPU。
| Framework | Model | NUM_THREADS | Throughput (tokens/sec) |
|---|---|---|---|
| T-MAC (CPU) | llama-2-7b (W4) | 2 | 12.6 |
| T-MAC (CPU) | llama-2-7b (W4) | 4 | 18.7 |
| T-MAC (CPU) | llama-2-7b (W2) | 1 | 9.3 |
| T-MAC (CPU) | llama-2-7b (W2) | 4 | 28.4 |
| NPE (NPU) | llama-2-7b (W4) | - | 10.4 |
3. 和 NVIDIA Jetson AGX Orin上的性能对比
NVIDIA Jetson AGX Orin 上的 Llama-2-7B (W2) 的吞吐量/功率/能量比较(CPU 的 NUM_THREADS=12)
| Framework | Throughput (tokens/sec) | Power (W) | Energy (J/token) |
|---|---|---|---|
| llama.cpp (CPU) | 7.08 | 15.0 | 2.12 |
| llama.cpp (GPU) | 20.03 | 30.8 | 1.54 |
| T-MAC (CPU) | 15.62 | 10.4 | 0.66 |







