
LLM模型之Turbo Sparse

LLM模型之Turbo Sparse
可爱可倾Turbo Sparse
通过最少的激活参数实现 LLM 的最先进性能 原文链接:Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
1. 简介
提出了一种新的基于drelu的稀疏化方法,在保持性能的同时,将模型稀疏性提高到90%,在推理中实现了2-5倍的加速。
1.1 性能提升
通过将我们的神经元稀疏化方法应用于Mistral和Mixtral模型,每次推理迭代分别只有25亿个和43亿个参数被激活,同时实现了更强大的模型性能。 评估结果表明,这种稀疏性实现了2-5倍的解码加速。在手机上,我们的TurboSparse-Mixtral-47B实现了11 tokens/s的推理速度。
2 概述
2.1 背景
为了解决现有密集模型固有的效率问题,条件计算已经成为一种关键方法,它指的是激活网络中的部分神经元。
- 混合专家(MoE): 通过在训练前手动设置模型架构上的约束来引入条件计算,例如确定要激活的专家数量。这种技术通过一个称为专家路由的过程,选择性地激活模型的特定部分,以响应特定的输入,从而显著提高效率;
- 利用ReLU激活函数自然产生的稀疏激活,它自然地输出零元素;
- 门控 MLP 块。在这种块中,激活函数的输出被门控,以便在每次迭代中只激活一部分神经元。
ReLUization 是一种现有的最先进的方法,用 ReLU 替换原始激活函数并继续预训练。尽管这种方法具有潜力,但往往难以达到所需的激活稀疏度水平,并可能导致性能下降。
我们认为现有 ReLUification 方法的失败可归因于两个主要原因。
- 首先,简单地用 ReGLU 替换 SwiGLU 是低效的,因为它只将稀疏性从 40% 增加到大约 70%。这表明有必要对模型架构进行更深入的研究,以实现更高水平的稀疏性。
- 其次,预训练数据的多样性有限,当前方法中训练tokens数量不足导致能力恢复不完整。因此,扩大预训练数据集的多样性并增加训练tokens的数量是提高模型性能的关键步骤。
2.2 创新
为了应对这些挑战,我们首先对现有的 ReLUfication 方法进行了综合分析,并确定其缺点源于 GLU 组件中的负激活。
因此,我们提出了一个名为 dReLU 的有效激活函数。
- 高效的dReLU激活函数: 使用不到150B个tokens,不到典型预训练tokens(通常为15T tokens)的1%。
- 稀疏激活模型: 两种稀疏激活TurboSparse-Mistral7B和TurboSparse-Mixtral-47B模型都比原始版本表现出更好的性能。
- 实际推理加速: 可以实现2-5倍的加速。值得注意的是,即使在TurboSparse-Mixtral-47B上没有GPU,我们也可以实现高达10 tokens/s的速度。
3 dReLU
3.1 核心
- 第一种改进 将 ReLU 化过程中的原始基于 SwiGLU 的前馈网络(FFN)替换为基于 dReLU 的前馈网络(FFN)。
- 第二种改进 是在第一种改进的基础上,通过稀疏机制进一步优化模型性能,通过控制稀疏水平来调整模型的激活值。
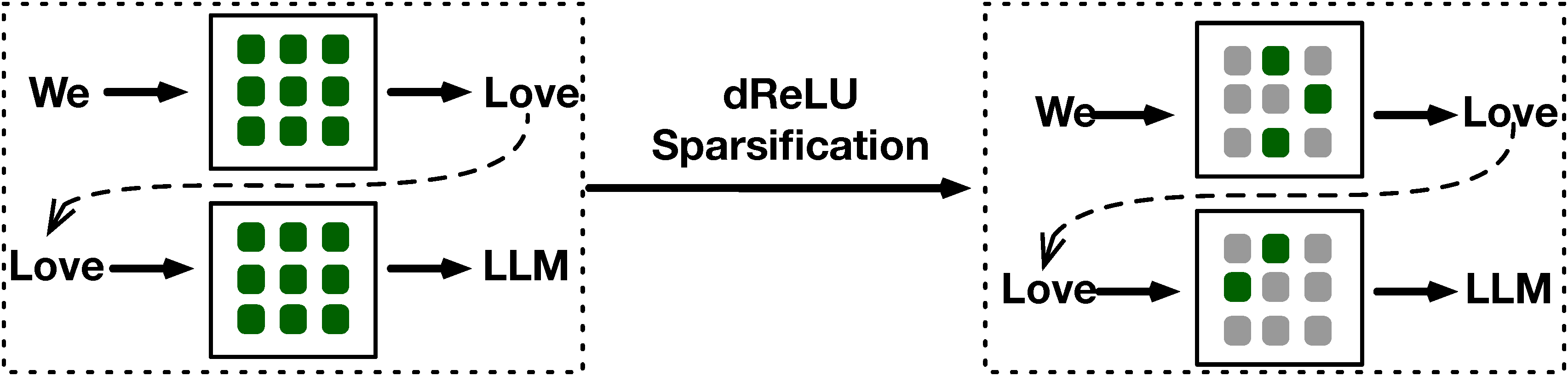 图1: dReLU Sparsification
图1: dReLU Sparsification
3.2 dReLU 激活函数
常用的 \(Gated-MLP\) 块由三个全连接层组成,并执行以下计算:
\[ \begin{aligned} \text{Gate}(x) &\coloneqq F_{act} (x W_{gate}) \\ \text{Up}(x) &\coloneqq x W_{up} \\ \text{Combined}(x) &\coloneqq \text{Gate}(x) * \text{Up}(x) \\ \text{Gated-MLP}(x) &\coloneqq \text{Combined}(x) W_{down} \end{aligned} \]
其中 \(F_{act}\) 代表不同的激活函数,\(W_{gate}\)、\(W_{up}\) 和 \(W_{down}\) 是权重矩阵。
3.2.1 使用 dReLU 激活函数
引入了一种新的激活函数 \(dReLU\):
\[ \begin{aligned} \text{Combined}_{\text{dReLU}}(x) &\coloneqq \max(0, x W_{gate}) * \max(0, x W_{up}) \end{aligned} \]
因此结合原本的 \(Gated-MLP\) 块,我们可以得到 \(Gated-MLP\) 块的 \(dReLU\) 版本:
- 使用 ((0, x W_{gate})) 计算门控激活(Gate)。
- 使用 ((0, x W_{up})) 计算向上投影(Up)。
- 将上述两步结果相乘以获得 Combined。
- 最后,将 Combined 通过下投影矩阵 (W_{down}) 生成最终输出。
\[ \begin{aligned} \text{Gate}(x) &\coloneqq \max(0, x W_{gate}) \\ \text{Up}(x) &\coloneqq \max(0, x W_{up}) \\ \text{Combined}_{\text{dReLU}}(x) &\coloneqq \text{Gate}(x) * \text{Up}(x) \\ \text{Gated-MLP}(x) &\coloneqq \text{Combined}_{\text{dReLU}}(x) W_{down} \end{aligned} \]
3.2.2 引入稀疏性机制
在上述 dReLU 激活函数的基础上,引入稀疏性机制,通过选择前 k% 的激活值,来控制模型的稀疏水平(在公式 3 的基础上加入以下):
- 计算 Combined 并生成其绝对值的前 k% 的掩码(Mask)。
- 将 Combined 乘以 Mask,以保留仅前 k% 的激活值。
- 将处理后的 Combined 通过下投影矩阵 (W_{down}) 生成最终输出。
\[ \begin{aligned} \text{Mask}(x) &\coloneqq \text{Top}_k(|\text{Combined}(x)|) \end{aligned} \]
\[ \begin{aligned} \text{Gated-MLP}(x) &\coloneqq (\text{Combined}(x) * \text{Mask}(x)) W_{down} \end{aligned} \]
3.3 PyTorch 实现(大概)
3.3.1 dReLU 激活函数
class dReLU(nn.Module):
def forward(self, x):
return torch.max(torch.zeros_like(x), x)
class GatedMLP(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(GatedMLP, self).__init__()
self.W_gate = nn.Linear(input_dim, hidden_dim)
self.W_up = nn.Linear(input_dim, hidden_dim)
self.W_down = nn.Linear(hidden_dim, output_dim)
self.drelu = dReLU()
def forward(self, x):
gate = self.drelu(self.W_gate(x))
up = self.drelu(self.W_up(x))
combined = gate * up
out = self.W_down(combined)
return out3.3.2 引入稀疏性机制
class dReLU(nn.Module):
def forward(self, x):
return torch.max(torch.zeros_like(x), x)
class SparseGatedMLP(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, k):
super(SparseGatedMLP, self).__init__()
self.W_gate = nn.Linear(input_dim, hidden_dim)
self.W_up = nn.Linear(input_dim, hidden_dim)
self.W_down = nn.Linear(hidden_dim, output_dim)
self.drelu = dReLU()
self.k = k # 稀疏水平
def forward(self, x):
gate = self.drelu(self.W_gate(x))
up = self.drelu(self.W_up(x))
combined = gate * up
# 在 Combined 中保留前 k% 的激活值
abs_combined = torch.abs(combined)
top_k_values, _ = torch.topk(abs_combined, int(self.k * combined.size(1)), dim=1)
min_top_k = top_k_values[:, -1].unsqueeze(1).expand_as(abs_combined)
mask = abs_combined >= min_top_k
masked_combined = combined * mask.float()
out = self.W_down(masked_combined)
return out






