
LLM模型之PowerInfer1.0

LLM模型之PowerInfer1.0
可爱可倾PowerInfer
在消费级 GPU 上的快速大语言模型推理 原文链接:PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
1 简介
利用LLM推理中固有的高局部性特性: 一个小子集的神经元(称为热神经元)在各种输入下始终被激活,而大多数神经元(称为冷神经元)则根据特定输入而变化。
PowerInfer利用这一见解设计了一个GPU-CPU混合推理引擎:
- 将热激活神经元预加载到GPU中以便快速访问,而冷激活神经元则在CPU上进行计算,从而显著减少了GPU内存需求和CPU-GPU数据传输。
- 集成自适应预测器和神经元感知稀疏算子,优化了神经元激活和计算稀疏性的效率。
- 自适应: 在DejaVu的基础上自适应两层MLP预测器(X-H-O)中隐藏层H的维度
- 神经元感知: 预测出激活的神经元,得到要算出这个神经元需要哪一行/列的权重,然后只计算这一行/列的权重
模型越大,优势越明显: 即主要针对的是模型比显存大时不能完全offload到GPU的情况。
1.1 核心
将少数的热神经元分配给GPU,而多数的冷神经元由CPU管理(GPU预加载经常激活的神经元的权重,而不太活跃的神经元的权重保留在CPU上)。离线预选择和预加载热激活神经元,并在运行时利用在线预测器来预测激活的神经元。
2 背景
2.1 稀疏激活的可能性
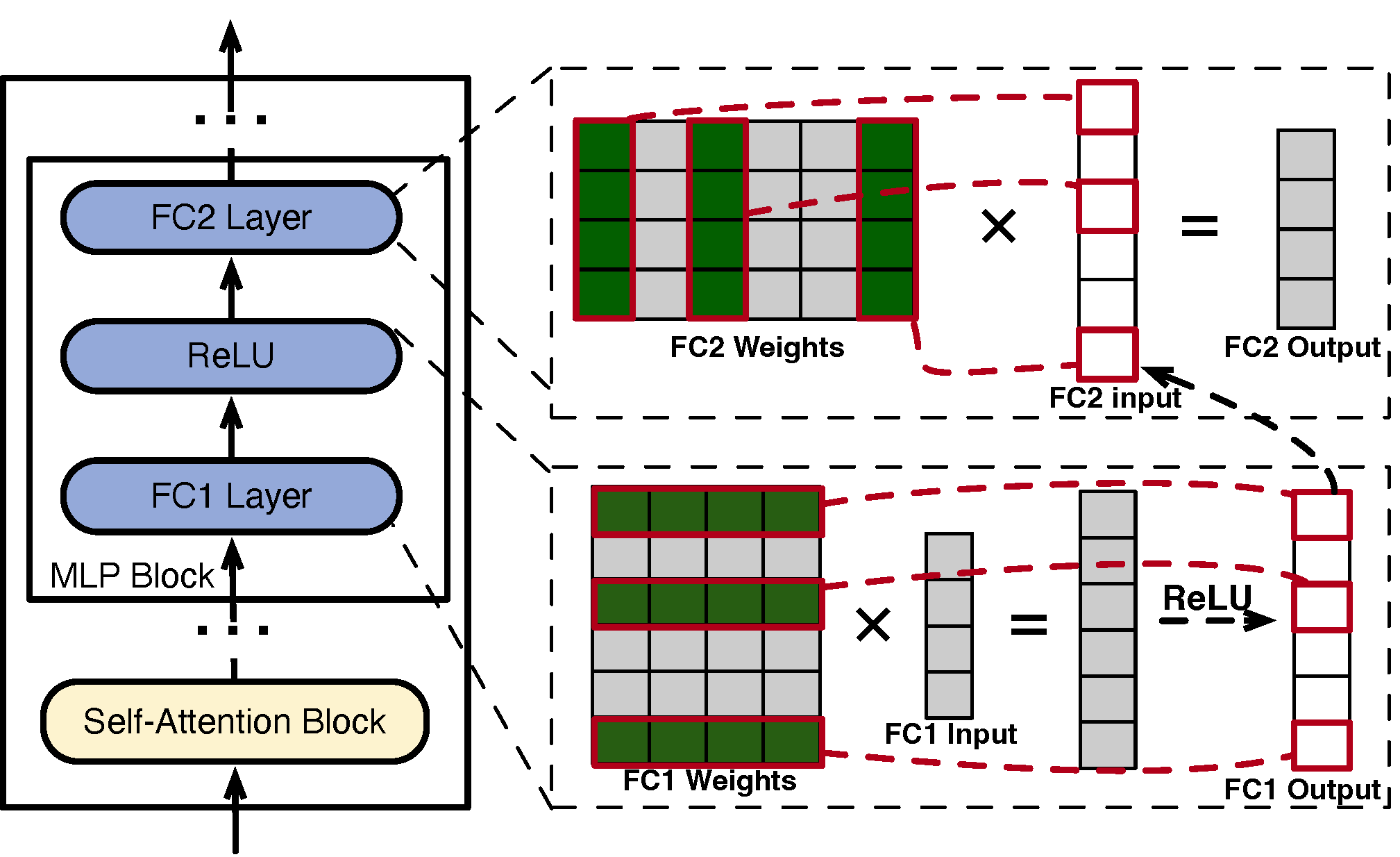 图1: 激活的神经元表示为由红线包围的绿色行或列, FC1 的输出向量提供给 FC2 作为其输入向量。
图1: 激活的神经元表示为由红线包围的绿色行或列, FC1 的输出向量提供给 FC2 作为其输入向量。
在图 1 中,MLP 块的层 FC1 和 FC2 通过矩阵乘法生成向量。每个输出元素都来自输入向量和神经元的点积(权重矩阵中的行/列)。ReLU 等激活函数充当门,选择性地保留或丢弃向量中的值,影响 FC1 和 FC2 中的神经元激活情况。
2.2 对LLM推理中的局部性的洞察
幂律激活 LLM推理表现出高度的局部性,表明一组一致的神经元经常被激活,从而可以分为热神经元和冷神经元。
CPU内快速计算 如果激活的神经元驻留在CPU内存中,则在CPU上计算它们比将它们转移到GPU更快。
3 PowerInfer 设计
- 为了减少推理延迟,在推理过程中仅计算在线预测器预测为活动的神经元。
- 预加载策略使PowerInfer能够将大部分推理任务分配给GPU,因为加载在GPU上的热激活神经元构成了激活的很大一部分。
- 对于冷激活神经元,在需要计算时仅在 CPU 上执行,消除了权重转移到 GPU 的需求。
3.1 架构与工作流程
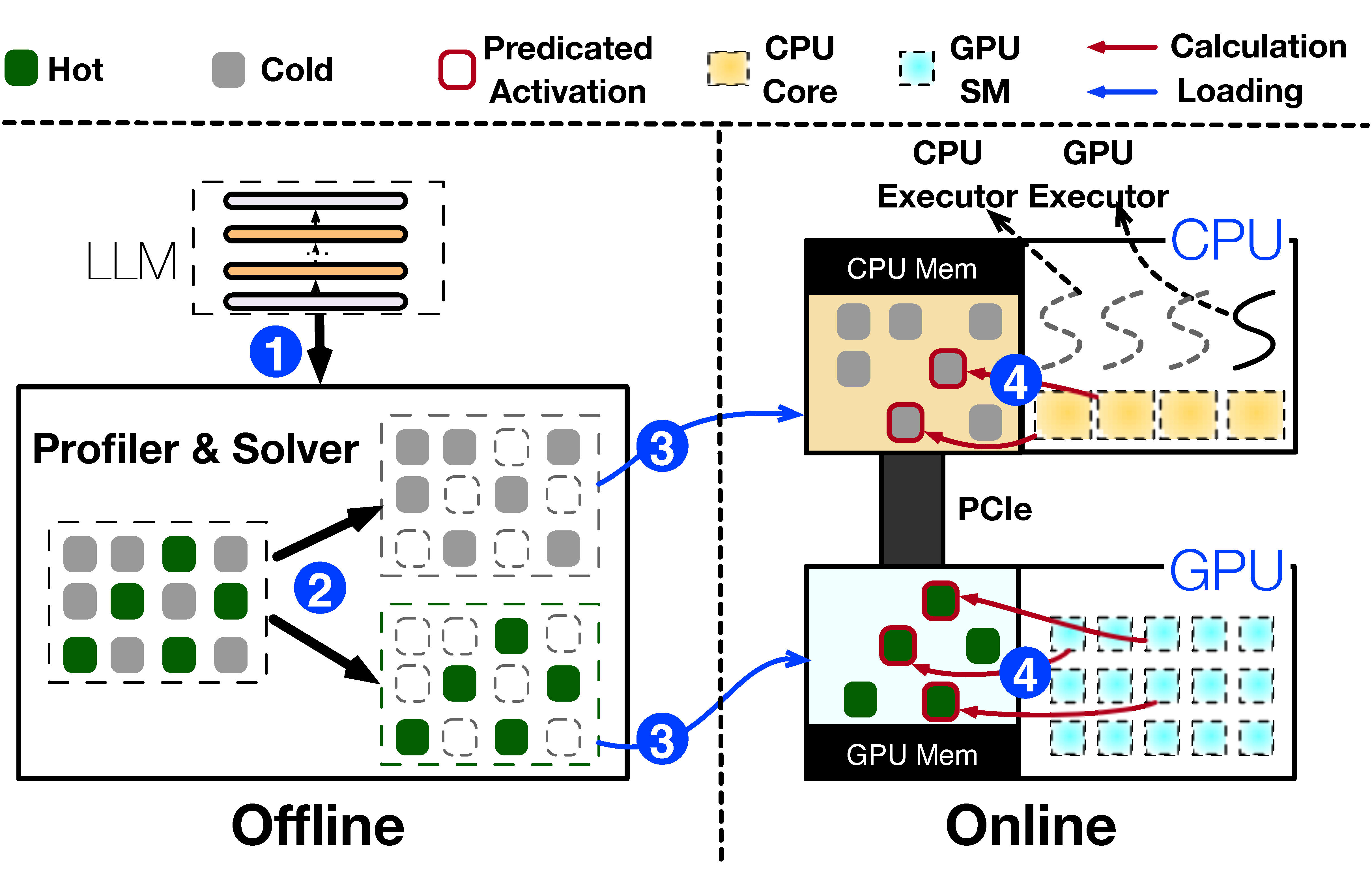 图2: PowerInfer架构
图2: PowerInfer架构
图 2 显示了 PowerInfer 的架构,包括离线和在线组件。
- 离线组件分析llm的激活稀疏性,区分热神经元和冷神经元。
- 在线阶段,推理引擎将两种类型的神经元加载到 GPU 和 CPU 中,并执行相应的计算。
LLM分析器和策略求解器(离线): 该组件包括一个 LLM 分析器,使用通用数据集得到。它监控所有层的神经元激活(步骤 ①),然后是将神经元分类为热或冷的策略求解器。求解器旨在将频繁激活的神经元分配给 GPU,将其他神经元分配给 CPU。在划分过程中使用整数线性规划来平衡工作负载(步骤 ②)。
神经元感知LLM推理引擎(在线): 在处理用户请求之前,根据离线求解器的输出,在线引擎将两种类型的神经元分配到各自的处理单元(步骤③)。在运行时,引擎创建 GPU 和 CPU 执行器,它们是运行在 CPU 侧的线程,以管理并发 CPU-GPU 计算(步骤 ④)。该引擎还预测神经元激活并跳过非激活神经元。在 GPU 内存中预加载的激活神经元在那里进行处理,而 CPU 将其神经元的结果计算并传输到 GPU 以进行集成。该引擎在 CPU 和 GPU 上使用稀疏神经元感知算子,专注于矩阵内的单个神经元行/列。
3.2 单层示例
图 3 说明了 PowerInfer 在处理层神经元时如何协调 GPU 和 CPU。
- 根据离线数据对神经元进行分类,将热激活神经元(索引 3、5、7)分配给 GPU 内存,将其他神经元分配给 CPU 内存。
- 在接收到输入后,预测器识别当前层中的哪些神经元可能被激活。例如,它预测神经元3、4和5的激活。
- 但是通过离线统计分析识别的热激活神经元可能不能一致地匹配运行时激活行为。例如,在这种情况下,神经元 7 虽然被标记为热激活,但被预测为不活跃。
- 然后 CPU 和 GPU 都处理预测的活动神经元,忽略非活动神经元。GPU计算神经元3和5,而CPU处理神经元4。
- 一旦神经元4的计算完成,其输出被发送到GPU进行结果集成。
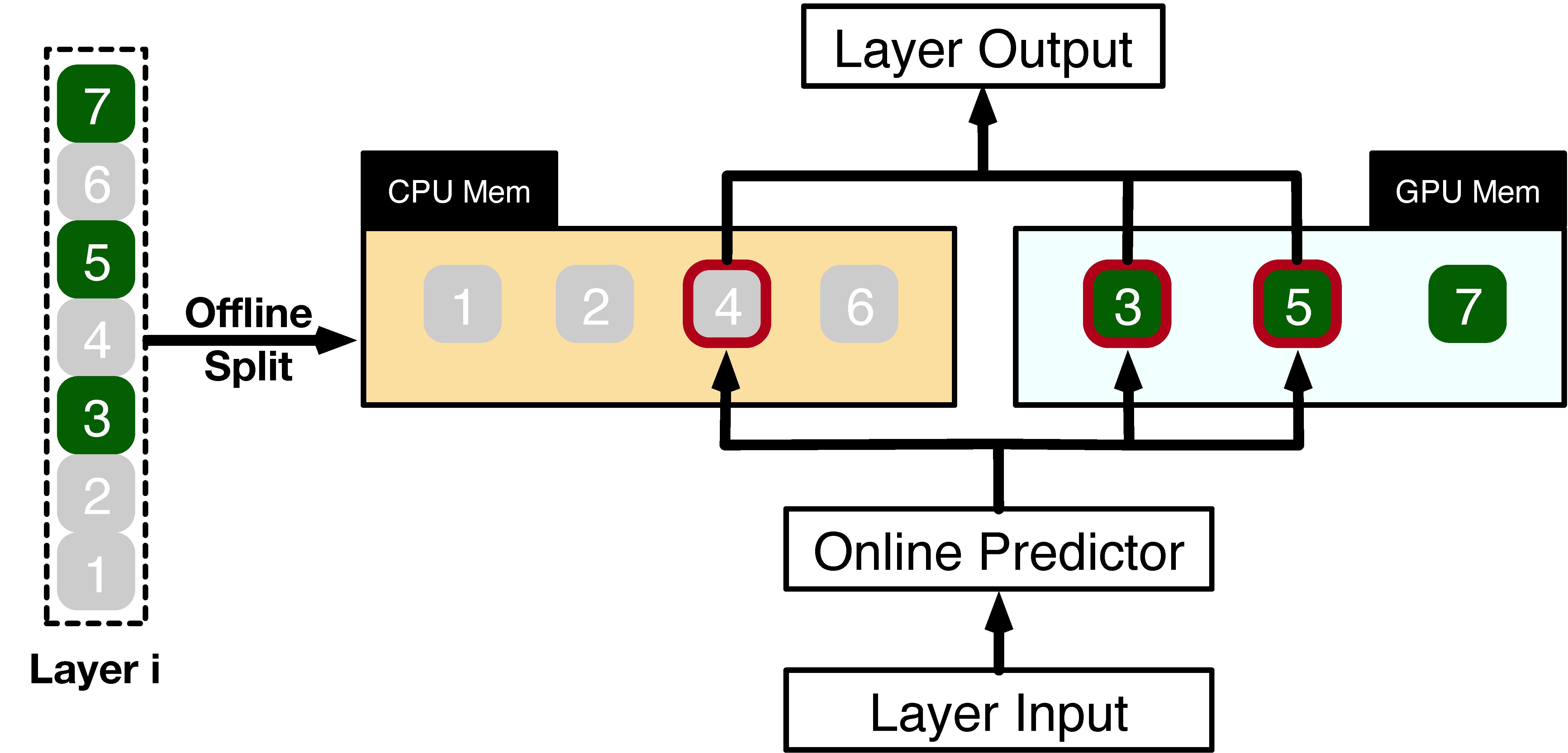 图3: 单层示例
图3: 单层示例
4 神经元感知推理引擎
PowerInfer 中的在线推理引擎通过仅处理那些被预测为激活的神经元来减少计算负载。
4.1 自适应稀疏预测器
预测器的大小受两个主要因素的影响:LLM 层的稀疏性及其内部偏度。(具有较高激活稀疏性或者高偏度的层简化了识别激活神经元的任务,从而允许较小的预测模型。)
PowerInfer在DejaVu的基础上为每个Transformer层设计了一种非固定大小的预测器的迭代训练方法(其实就是自适应两层MLP预测器(X-H-O)中隐藏层H的维度):
- 首先基于层的稀疏配置文件建立基线预测器模型大小。
- 随后,在考虑内部激活偏度以保持准确性的情况下,迭代地调整模型大小。(MLP 预测器通常包括输入、隐藏层和输出层。由于输入和输出层的维度由 Transformer 层的结构决定,因此修改主要针对隐藏层)
- 在迭代调整过程中,隐藏层的维数根据观测到的偏度进行修改。(对于具有明显偏度的层,隐藏层的大小逐渐减小,直到精度降至95%以下。相反,对于具有最小偏度的层,则增加尺寸以提高精度。)
通过这种方法,PowerInfer有效地将MLP预测器参数限制在LLM总参数的10%以内。
4.2 神经元放置和管理
把神经元拆分开了,那计算的时候如何确保计算位置是对的?
创建两个神经元表,一个位于 CPU 中,另一个位于 GPU 内存中。这些表将每个神经元与其矩阵中的原始位置相关联。在与输入张量相乘的过程中,由神经元表指导。
4.3 GPU-CPU混合执行
GPU-CPU两个单元独立计算它们各自的激活神经元,然后在 GPU 上组合结果。
- 在推理之前,构造一个计算图,每个节点代表一个 LLM 推理算子,并将其存储在 CPU 内存中的全局队列中。队列中的每个运算符都标有其先决条件运算符。
- 在推理过程中,主机操作系统创建的两种类型的执行器 pthreads 管理 CPU 和 GPU 的计算。它们从全局队列、检查依赖项中提取运算符并将它们分配给适当的处理单元。
- GPU 和 CPU 使用他们的神经元感知运算符,GPU 执行器使用 cudaLaunchKernel 等 API 启动 GPU 运算符,以及协调未占用 CPU 内核以进行计算的 CPU 执行器。在执行运算符之前,CPU 执行器还确定并行计算的必要线程计数。
- 为了管理运算符依赖关系,尤其是当 CPU 运算符的父节点在 GPU 上处理时,确保 GPU 计算在 CPU 启动其运算符之前完成。
GPU和CPU选择性同步策略: 在一个单元完成其神经元计算后,它等待另一个合并结果。由于 GPU 神经元更频繁地被激活,PowerInfer 将合并操作分配给 GPU。当CPU执行器没有激活神经元时绕过结果同步,使其能够继续后续块,从而提高整体效率。
4.4 神经元感知算子
考虑到llm的激活稀疏性,矩阵乘法操作可以使用稀疏算子绕过不活跃的神经元及其权重。PowerInfer 引入了一种神经元感知算子,专注于矩阵中的单个行/列向量而不是整个矩阵。
GPU 的神经元感知算子: 尽管GPU上 向量-向量计算 比 矩阵-向量计算 效率更低,但是在神经网络中通常有大量非活动神经元,基于 向量-向量计算 的算子可以跳过这些非活动神经元,避免不必要的计算和内存,并且不需要昂贵的矩阵转换。
CPU 的神经元感知算子: CPU通常具有较低的并行性和矩阵计算效率,所以这种情况下 向量-向量计算 非常有利。CPU执行器为多核分配一个神经元感知算子,将神经元分成更小的批次进行并发激活检查。每个核心只处理其批次中的激活神经元,使用 AVX2 等硬件向量扩展优化 向量-向量计算。
5 神经元放置策略
PowerInfer 的离线组件提供了一种放置策略,以指导每个神经元分配给 GPU 或 CPU。
5.1 离线分析
在确定每个神经元的位置之前,PowerInfer 的离线分析器需要为每个神经元收集运行时推断数据(就是推理通用数据集然后统计频繁激活的神经元)。
- 部署LLM来处理从多个通用数据集生成的请求。
- 分析器在 Transformer 层内的每个块之后插入一个监控内核(检查层中的每个神经元是否在推理过程中被激活,如果是,增加神经元表中相应的计数)
- 在 GPU 上构建了一个神经元信息表,旨在跟踪每个神经元的激活计数。
5.2 神经元影响度量
神经元影响度量测量每个神经元对LLM整体推理结果的贡献。我们通过利用分析激活频率准确反映运行时行为的事实来有效地计算该指标:
\[ \begin{gather*} v_{i} = f_{i} \hspace{1cm}\forall i \in \mathbb{N} \tag{1} \end{gather*} \]
5.3 神经元放置建模
基于神经元影响度量,PowerInfer 利用求解器来优化 GPU 中所有神经元的总影响。这个累积影响被表述为目标函数,如式 2 所示。然后将该函数输入到整数线性规划框架中,以识别最大化函数的特定解。等式 3 中定义的二元变量 \(a_{in}\) 表示神经元是否放置在处理单元 \(i\) 上。
\[ \begin{gather*} Maximize \quad t_i= \sum_{e \in \mathbb{N}} a_{ie} * v_{e} \forall i \in \{GPU\} \tag{2} \\ \sum_{i \in \mathbb{U}} a_{in} = 1 \quad\forall n \in \mathbb{N} \tag{3} \end{gather*} \]
5.3.1 通信约束
在GPU上预加载的神经元数量受到层内通信开销的限制。如果预加载了太少的神经元,这种开销会否定 GPU 提供的计算优势。因此,求解器必须识别最少数量的神经元来分配给 GPU 进行处理。在不等式 4 中,\(C_{l}\) 是必须分配给第 \(l\) 层的 GPU 的神经元的最小计数。具体来说,GPU 上层 \(l\) 的神经元数必须超过 \(C_{l}\) 或等于 0。
在求解不等式 4 时,必须定义第 \(l\) 层单个神经元的计算时间和层内通信开销。在LLM推理中,特别是在较小的批处理大小下,该过程主要受内存带宽的限制。因此,神经元的计算时间大致等于一次访问所有权重所需的时间,如公式 5 所示。在较小的批处理大小下,层内数据传输的程度往往跨层一致,导致同步成本均匀。
\[ \begin{gather*} C_{l} \cdot T_{l}^{GPU} + T_{sync} \leq C_{l} \cdot T_{l}^{CPU} \forall l \in \mathbb{L} \tag{4} \\ T_{i}^{j} = M_{i} / Bandwidth_{j} \quad \forall j \in \mathbb{D}, \forall i \in \mathbb{L} \tag{5} \\ \end{gather*} \]
5.3.2 内存约束
神经元放置进一步受到处理单元的内存容量的限制,如不等式 6 所示。
我们引入了一个辅助二进制变量\(y_l\),它可以是1或0。这个变量决定了任何神经元是否分配给第\(l\)层的GPU。为方便起见,还引入了足够大的 \(K\)。
等式 7 和 8 被制定为对这种约束进行建模。当 \(y_l\) 为 1 时,表示该层 GPU 上的神经元放置,鉴于 \(K\) 足够大,这两个不等式有效地变为 \(y_l \leq \sum_{e \in N_l} a_{ie} \leq K\)。相反,如果 \(y_l\) 设置为 0,表示层 \(l\) 的 GPU 上没有神经元放置,则不等式减少到 \(\sum_{e \in N_l} a_{ie} = 0\)。
\[ \begin{gather*} \sum_{n \in N} a_{jn} \cdot M_{n} < MCap_j \quad \forall j \in \mathbb{U} \tag{6} \\ \sum_{e \in N_l} a_{ie} \geq C_l \cdot y_l \quad \forall l \in \mathbb{L}, \forall i \in \{GPU\} \tag{7} \\ \sum_{e \in N_l} a_{ie} \leq K \cdot y_l \quad \forall l \in \mathbb{L}, \forall i \in \{GPU\} \tag{8} \end{gather*} \]
5.3.3 ILP优化
随后,求解器利用整数线性规划 (ILP) 来优化目标函数,符合等式/不等式 3 到 8 的所有约束。为了加快 IPL 过程并实现近似解,主要策略是将每一层的神经元聚合成批次以进行集体放置分析。
附录
DejaVu
核心方法是在推理阶段,利用当前输入\(X\)动态地选择部分网络参数来进行推理,而不使用全参。所以可以将其看作是一种“动态剪枝”的方法。
原文中指出: 在实际推理过程中,我们可以只使用约20%的Attention head和约5%的MLP神经元,就能达到和全参模型差不多的效果。
 图4: DejaVu
图4: DejaVu
如何基于输入\(X\)从预训练好的LLM A中快速产生LLM B,使得LLM B在\(X\)上的推理结果与LLM A在\(X\)上的推理结果尽可能一致?
在DejaVu中使用了两个模型来做预测,这两个模型的实现都使用了一个两层MLP。第一个模型用来预测MHA中哪些head是“高效的”;第二个模型用来预测MLP中哪些神经元是“高效的”(神经元实际上对应于参数矩阵的某一列或某一行)。
以预测Attention的head编号为例,假设head数为256,只需要将MLP的输出层的大小设为256,并为每一个输出使用sigmoid来做一个二分类即可(“选择”or“不选择”)。训练数据依靠一个完整的、训练好的LLM来产生。在这个LLM的推理过程中,通过记录它的Attention输入和Attention输出,并计算不同head的L2 Norm,再基于一个L2 Norm的阈值t将head分为正例和负例。
假设当前的Transformer模块为网络的第 \(l\) 层(不同网络层使用的稀疏性预测模型是不同的),它对应的MHA和MLP稀疏性预测模型记为 \(\mathsf{SP}_A^{l}\) 和 \(\mathsf{SP}_M^{l}\) ,输入为\(y_l\)。 大概过程如下:
\[ \begin{align*} S_A^l \leftarrow \mathsf{SP}_A^{l}(y_l), \quad \widetilde{y}_l \leftarrow \mathsf{MHA}^{l}_{S_A^l}(y_l), \\ S_M^l \leftarrow \mathsf{SP}_M^{l}(\widetilde{y}_l ), \quad \widehat{y}_l \leftarrow \mathsf{MLP}^{l}_{S_M^l}( \widetilde{y}_l) \end{align*} \tag{-1} \]
其中,\(S_A^l\)和\(S_M^l\)分别是Attention和MLP的上下文稀疏度。
- KV cache 缺失的处理: 对于在计算过程中,会为不被选择的注意力头保存一份过往token的副本,在下一次计算时,如果这个头被选择了,并且缺少KV cache,此时就会加载存储的token嵌入并一起计算K/V
- 即使减少了部分FFN和注意力头,稀疏预测开销可能很容易增加而不是减少端到端延迟: 因为注意力和MLP块的计算必须等待稀疏预测器的决定。就延迟而言,这种开销可能超过了注意力和MLP块的节省。鉴于此,引入了一种前瞻性稀疏预测方法。研究发现了:嵌入特征缓慢演变,即可以用\(y_l\)来预测\(l+1\)层的稀疏性。从而实现并行化。 \[ \begin{align*} \widetilde{y}_l \leftarrow \mathsf{MHA}^{l}_{S_A^l}(y_l), \quad \widehat{y}_l \leftarrow \mathsf{MLP}^{l}_{S_M^l}( \widetilde{y}_l ), \\ S_{A}^{l+1} \leftarrow \mathsf{SP}_A^{l}(y_l), \quad S_M^{l+1} \leftarrow \mathsf{SP}_M^{l}(y_l), \end{align*} \tag{-2} \]
- 其他trick: 将稀疏矩阵的索引和乘法操作合并为一个单一的内核,以及采用了其他一些内存对齐技术以保证高效执行。
原文链接:Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time 参考
其他
- 大于总内存的模型怎么放到机器上
- 对于PowerInfer1,模型首先在CPU上加载,然后将热激活神经元根据模型保存的激活文件信息卸载到GPU上。
- 至于PowerInfer-2,则是创建一个LRU缓存,将频繁使用的(热激活)神经元放到DRAM中,超出LRU缓存大小的(冷)神经元放在RAM,然后计算的时候如果命中LRU缓存,直接计算,如果没有,则跳过该神经元计算下一个神经元,并同时开始IO操作。这样可以先计算在DRAM中的神经元,然后再计算在RAM中的神经元,这种并行可以减少IO操作的影响。
- DejaVu 增加了计算怎么比原来计算快
- DejaVu 通过动态剪枝的方式,减少了计算量
- 稀疏预测器进行并行预测,在第t步时预测第t+1步的稀疏性,减少等待时间
- Kernel fusion: 将稀疏矩阵的索引和乘法操作合并为一个单一的内核
- 内存对齐技术: 减少IO操作的影响
- 为什么在下投影层实现AXPY算子来计算稀疏矩阵,而上投影层则是正常的vec_dot形式的矩阵乘法
- 这是考虑到了神经元的激活在下投影层是按列的,导致了下投影层加载时的不连续性,decoding阶段LLM推理是memory bandwidth bound的,实现思路就是尽可能保证连续的load,并且跳过不必要的memory access。尽管GPU上shared memory是可以从HBM先不连续的load进来再进行计算,但是CPU上的cache没办法显式控制,AXPY可以保证CPU/GPU都能做到连续的memory access,因此设计了AXPY。
- 如图1所示,在下投影计算的时候,每一行的元素是稀疏激活的,激活的列数据是连续的,因此在计算时先判断是否激活,如果激活则将对应的列加载到cache中,然后进行计算,如果不激活则跳过该列。将以行为基准的稀疏矩阵转换为以列为基准的稀疏矩阵。







