
LLM模型之KTransformers

LLM模型之KTransformers
可爱可倾KTransformers
KTransformers KTransformers 是一个灵活的、以 Python 为中心的框架,旨在通过高级内核优化和放置/并行策略增强 transformers
KTransformers的Github链接 DeepSeek V2的Github链接 DeepSeek V2的论文链接
1. 介绍
KTransformers 的核心是一个用户友好的、基于模板的注入框架。
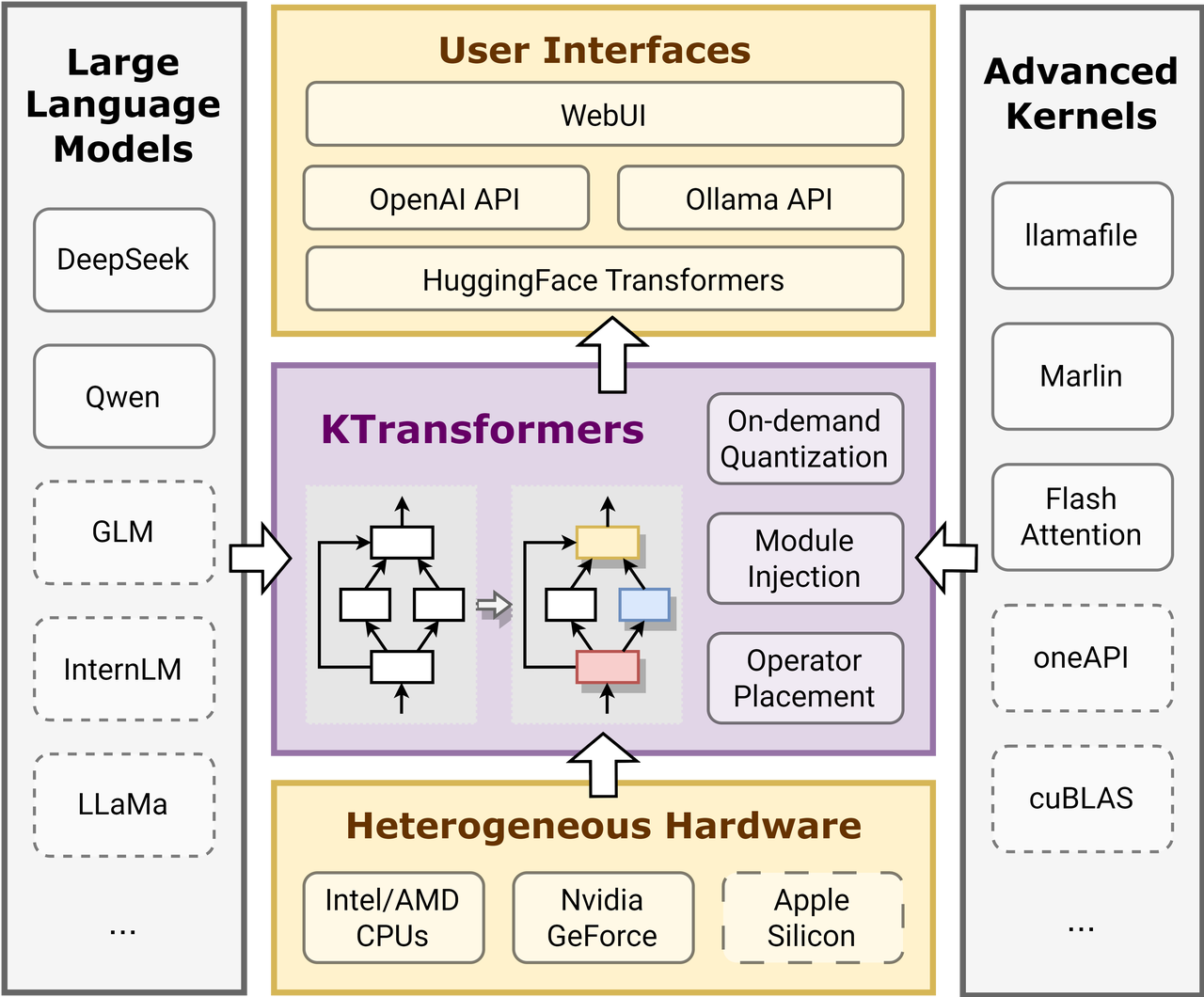 图1:KTransformers 架构
图1:KTransformers 架构
2. 优化技术
KTransformers采用了多种优化技术,将需要两块80GB显存GPU的 DeepSeek-V2 Q4_k_m 模型运行在21GB显存和136GB内存的台式计算机上。
2.1 MLA 注意力机制
DeepSeek V2 的 MLA 官方开源明确地解压了MLA的压缩表示,并缓存了解压后的键值对。针对此,KTransformers 对DeepSeek V2 的MLA按照原文进行了实现,将解压缩矩阵直接吸收到 q_proj 和 out_proj 权重中,减少了 KV 缓存大小并增加了该算子的算力强度,从而大大优化了 GPU 计算能力的利用率。
2.1.1 DeepSeek V2 的MLA
DeepSeek V2 设计了 MLA,它利用低秩键值联合压缩来消除推理时间键值缓存的瓶颈,从而支持有效的推理。
 图3:DeepSeek MLA 架构
图3:DeepSeek MLA 架构
2.1.1.1 MLA的提出
MLA的核心是对键和值进行低秩联合压缩,以减少KV缓存:
 图4:MLA 架构
图4:MLA 架构
Attention的计算公式为\(A = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\),其中\(Q,K,V\)分别为查询、键、值,\(d_k\)为键的维度。
假定输入是\(x\),对\(x\)做一个低秩转换:
\[ \begin{aligned} \textcolor{red}{c} &= xW^C \quad W^C \in \mathbb{R}^{d_{\text{model}} \times d_c} \quad x \in \mathbb{R}^{n \times d_{\text{model}}} \end{aligned} \]
接着计算每一个head的\(Q,K,V\):
\[ \begin{aligned} Q &= xW^Q \quad W^Q \in \mathbb{R}^{d_{\text{model}} \times d_k}\\ K &= xW^K = \textcolor{red}{c}W^{K'} \quad W^K \in \mathbb{R}^{d_{\text{model}} \times d_k} \quad W^{K'} \in \mathbb{R}^{d_{\textcolor{red}{c}} \times d_k}\\ V &= xW^V = \textcolor{red}{c}W^{V'} \quad W^V \in \mathbb{R}^{d_{\text{model}} \times d_v} \quad W^{V'} \in \mathbb{R}^{d_{\textcolor{red}{c}} \times d_v}\\ QK^T &= xW^Q(\textcolor{red}{c}W^{K'})^T = x(W^QW^{K'T})\textcolor{red}{c}^T \end{aligned} \]
此时如果有\(W^{Q'}=W^QW^{K'T}\)(会不会有精度损失?)
且 \(W^{Q'} \in
\mathbb{R}^{d_{\text{model}} \times d_c}\),则\(QK^T=xW^{Q'}\textcolor{red}{c}^T\),在推理过程中不需要再缓存K
V 矩阵,只需要缓存 \(\textcolor{red}{c}\) 矩阵,如下:
\[ \begin{aligned} A &= \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V \\ &= \text{softmax}(\frac{xW^{Q'}\textcolor{red}{c}^T}{\sqrt{d_k}}){\textcolor{red}{c}W^{V'}}\\ \end{aligned} \]
\(\textcolor{red}{注意}\):这里的\(\textcolor{red}{c}\)是从\(x\)得到的,也就是说在每一个Layer,所有的Attention-Head使用的都是一个同样的\(\textcolor{red}{c}\),而不是每个Head都使用不同的K
V矩阵。参数从\(2 \times
head\) 变为了 \(\textcolor{red}{1}\)。
从上面的公式可以看出,MLA实际上是一个MHA,但是KV_Cache占用甚至少于GQA。再次回顾图3,可以清晰看出区别。
其中\(d_{\textcolor{red}{c}}\) 是超参数,\(d_{\text{model}}\) 是模型维度,\(d_k\) 是键的维度,\(d_v\) 是值的维度。
问题1:和GQA,MHA对比不同之处
如果考虑所有头维度加起来的话:
\[ n_{head} \times d_{k}= \begin{cases} d_{model} & \text{MHA} \\ (1,d_{model}) & \text{GQA} \\ \end{cases} \]
\(W^Q\)和\(W^K\)的大小是\(\mathbb{R}^{d_{\text{model}} \times d_k}\),\(W^V\)的大小是\(\mathbb{R}^{d_{\text{model}} \times d_v}\)。
\(W^{Q'}\)的大小是\(\mathbb{R}^{d_{model} \times d_{\textcolor{red}{c}}}\),\(W^{Q'}\)和\(W^{V'}\)不存在了,\(W^{O'}\)的大小是\(\mathbb{R}^{d_{\textcolor{red}{c}} \times d_{model}}\)。DeepSeek V2 选择的是\(d_{\textcolor{red}{c}} = 4\times d_k\)。
所以MLA当\(d_{\textcolor{red}{c}} = d_k\)时就是正常的MHA。
问题2:和正常的Attention对比,为什么不进一步cache x
正常的Attention计算如下:
\[ \begin{aligned} A &= \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V \\ &= \text{softmax}(\frac{xW^QW^{KT}x^T}{\sqrt{d_k}}){xW^V} \end{aligned} \]
和上文介绍的对比,为什么不直接保存\(x\),而去保存\(c\)?
- 保存\(x\)就是不做KV_Cache的情况:或者说保存\(x\),把\(W^K\)吸收到\(W^Q\)中这时候的\(W^{Q'}\)的大小是\(\mathbb{R}^{d_{\text{model}} \times d_{\text{model}}}\),而保存\(c\)的时候\(W^{Q'}\)的大小是\(\mathbb{R}^{d_{\text{model}} \times d_c}\)。通常\(d_{\text{model}} \gg d_c\),所以保存\(x\)的计算量更大。
- 保存全量KV_Cache就是通常的KV_Cache的做法
- 而保存\(c\)则是折中:降低显存和加载代价, 而提升计算代价
这也是整个方法的核心思想。
2.1.1.2 不兼容ROPE
但是当加入ROPE后就会存在问题:
\[ f_{\{q, k\}}\left(\boldsymbol{x}_{m}, m\right)=\boldsymbol{R}_{\Theta, m}^{d} \boldsymbol{W}_{\{q, k\}} \boldsymbol{x}_{m} \]
其中\(\boldsymbol{R}_{\Theta, m}^{d}\) 是旋转矩阵,\(\boldsymbol{W}_{\{q, k\}}\) 是权重矩阵,\(\boldsymbol{x}_{m}\) 是输入。
\[ \begin{aligned} Q &= xW^QR^Q\\ K &= xW^KR^K\\ QK^T &= xW^QR^Q(xW^KR^K)^T\\ &= xW^QR^Q(cW^{K'}R^K)^T\\ &= x(W^QR^{Q-K}W^{K'T})c^T\\ \end{aligned} \]
此时的\((W^QR^{Q-K}W^{K'T})\)因为加入了位置信息,所以不再是常数,所以无法像MLA一样进行优化。
所以DeepSeek V2 采取了一种混合的方法——每个Attention Head的Q、K新增 \(dr\) 个维度用来添加RoPE,其中K新增的维度每个Head共享(注1):
\[ \begin{aligned} Q &= [xW^{Q'}, xW^{Qr}R^Q] \in \mathbb{R}^{d_{model} \times (d_{\text{k}}+dr})\\ K &= [cW^{K'}, xW^{Kr}R^K] \in \mathbb{R}^{d_{model} \times (d_{\text{k}}+dr)}\\ \end{aligned} \]
此时的矩阵中\(xW^{Q'}\)就不携带位置信息,所以可以像MLA一样进行优化。 而\(xW^{Qr}R^Q\)和\(xW^{Kr}R^K\)则携带位置信息。
此时在推理过程KV_Cache中,只需要多缓存一个\(xW^{Kr}R^K\)(命名为K^r)。 即只需要缓存\(\textcolor{red}{c}\)和\(\textcolor{red}{K^r}\)。
论文中选取的参数如下:
| 参数 | 值 |
|---|---|
| \(d_{\text{model}}\) | 5120 |
| \(d_k\) | 128 |
| \(d_c\) | 512 |
| \(dr\) | 64 |
注1: 虽然不同的注意力头有各自独立的 \(k_{head}\),但这些新增的 \(dr\) 个维度是相同的,所有头在这些维度上使用的是相同的位置编码信息。这与标准多头注意力中的做法一致,在标准多头注意力中,尽管每个头有不同的键向量\(k_{head}\),但这些键向量的位置编码信息是相同的,因为每个Attention Head输入都是一样的。这种共享有助于在不同的头之间保持位置信息的一致性,从而让每个头能够以一致的方式利用位置信息,尽管它们在关注的内容上可能有所不同。
2.1.1.3. Query 低秩
DeepSeek V2 还将 \(Q\) 也转化为了低秩矩阵,这并不会减少KV_Cache的存储量,文中称可以减少训练期间参数量和相应的梯度。
\[ \begin{aligned} Q &= [c^{'}W^{Q'}, c^{'}W^{Qr}R^Q] \in \mathbb{R}^{d_{model} \times (d_{\text{k}}+dr})\\ K &= [cW^{K'}, xW^{Kr}R^K] \in \mathbb{R}^{d_{model} \times (d_{\text{k}}+dr)}\\ \end{aligned} \]
其中\(d_{c^{'}}\)是一个超参数,\(d_{c^{'}}=1536\)。
2.1.2 KV_Cache和FLOPs的权衡
减少部分KV Cache,增加部分计算量,在保存全量KV_Cache和不保存KV_Cache之间取得了一个折中。如下:
1. 训练阶段 MLA基本相当于把MHA的每个Attention Head 中的\(Q,K\)维度从\(d_k\)变为了\(d_c+dr\)。
2. 推理阶段
由于\(d_{\textcolor{red}{c}} = 4\times d_k\),实际上MLA在推理阶段做的这个转换,虽然能有效减少KV Cache,但其推理的计算量是增加的。
2.1.2.1 KV_Cache
| Attention Mechanism | KV_Cache per token | Capability |
|---|---|---|
| MHA | \(2n_hd_hl\) | Strong |
| GQA | \(2n_gd_hl\) | Moderate |
| MQA | \(2d_hl\) | Weak |
| MLA | \((d_c+d_r)l \approx 4.5d_hl\) | Strong |
其中\(d_h\)是head维度,\(n_h\)是head数,\(n_g\)是gqa head数。
所以大概等效于\(n_g=2.25\)的GQA的KV_Cache,相比于8个head的GQA大概降低到了原来的0.28倍。
2.1.2.2 FLOPs
因为正常来讲\(W^Q\)的大小是\(\mathbb{R}^{d_{\text{model}} \times d_k}\),\(W^O\)的大小是\(\mathbb{R}^{d_v \times d_{\text{model}}}\)。而在MLA中\(W^{Q'}\)的大小是\(\mathbb{R}^{d_{\text{model}} \times d_c}\),\(W^{O'}\)的大小是\(\mathbb{R}^{d_c \times d_{\text{model}}}\)。所以在推理阶段,MLA的计算量是增加的。
具体增加了多少
假设输入的batch为\(b \times s \times d\),其中\(b\)为batch_size,\(s\)为输入长度,\(d\)为嵌入维度
- Embedding层:查表操作,不涉及矩阵乘法,故不计入FLOPs
- 预测多分类头(logits)将尺寸为 d 的隐藏向量映射为词表大小:\([b \times s \times d] \times [d \times V] = [b \times s \times V]\) —— \(2bsVd\)
- Self-Attention层: \[
Q'=xW^{Q'}\\
Attention =
\text{softmax}(\frac{Q'\textcolor{red}{c'}^T}{\sqrt{d_k}}){\textcolor{red}{c}}\\
x_{out}= AW^{O'}+x
\]
- 每个头的注意力计算:一下需要乘\(n_{heads}\)次,每次计算如下:
- 计算 Q’ 矩阵:\([b \times s \times d] \times [d \times d_{c'}] = [b \times s \times d_{c'}]\) —— \(2bsdd_{c'}\)
- 计算注意力权重\(Q'{c'}^T\):\([b \times s \times d_{c'}] \times [b \times s \times d_{c'}]^T = [b \times s \times s]\) —— \(2bs^2d_{c'}\)
- 汇聚价值信息\(Ac\): \([b \times s \times s] \times [b \times s \times d_c] = [b \times s \times d_c]\) —— \(2bs^2d_c\)
- 拼接多头注意力: 不涉及矩阵乘法,故不计入FLOPs
- 输出矩阵\(O\): \([b \times s \times (n_{heads}\times d_c)] \times [(n_{heads}\times d_c) \times d] = [b \times s \times d]\) —— \(2bsd(n_{heads}\times d_c)\)
- 每个头的注意力计算:一下需要乘\(n_{heads}\)次,每次计算如下:
- MLP层:\(16bsd^2\) \[
h=Relu(x_{out}W^1+b_1)\\
h_{out}=hW^2+b2\\
x=h_{out}+x_{out}
\]
- 第一个线性层:\([b \times s \times d] \times [d \times 4d] = [b \times s \times 4d]\) —— \(8bsd^2\)
- 第二个线性层:\([b \times s \times 4d] \times [4d \times d] = [b \times s \times d]\) —— \(8bsd^2\)
| 模块 | 数量 | 单次FLOPs | 总FLOPs |
|---|---|---|---|
| Embedding | 1 | 0 | 0 |
| LM Head(logits) | 1 | \(2bsVd\) | \(2bsVd\) |
| Self-Attention | l | \(2bsn_{heads}(2dd_c+dd_r+2sd_c+sd_r)\) | \(2blsn_{heads}(2dd_c+dd_r+2sd_c+sd_r)\) |
| MLP | l | \(16bsd^2\) | \(16blsd^2\) |
| 正常的MHA FLOPs | - | - | \(2bsVd + 24blsd^2 + 4bls^2d\) |
其中\(l\)为层数,\(d\)为嵌入维度,\(s\)为输入长度,\(V\)为词表大小,\(b\)为batch_size,\(n_{heads}\)为head数。
\[ \begin{aligned} FLOPs(MLA/MHA) &\approx \frac{16blsd^2+2blsn_{heads}(2dd_c+dd_r+2sd_c+sd_r)}{24blsd^2 + 4bls^2d}\\ &= \frac{33d+17s}{24d+4s}(\textcolor{red}{存疑})\\ \end{aligned} \]
2.1.3 DeepSeek V2 的MOE
另外 DeepSeek V2 是一个改进的MOE模型,部分改动如下:
- 细粒度专家分割:通过将每个FFN专家进一步细分,这允许模型在保持参数总数不变的情况下,激活更多的、更细粒度的专家。这种策略使得各个专家能够专注于更细致的知识领域,提高了专家的专业化程度。
- 共享专家隔离:设置一部分专家作为“共享专家”,这些专家总是被激活,用于捕捉和整合常见的跨上下文知识。这样可以减少路由专家之间的知识冗余,避免重复知识,每个路由专家可以更专注于独特的知识领域。
2.2 改进的量化内核
Transformers 的 Torch 实现必须在处理之前将这些张量反量化为支持的数据类型,这会带来不必要的计算开销并增加内存流量。为了克服这个问题,我们加入了直接对量化数据类型进行操作的高级内核,从而优化了推理性能。
2.3 计算强度引导的模型加载
遵循按算术强度排列所有算子并尽可能将最密集的算子放在 GPU 中的原则,策略性地只将计算最密集的参数存储在 GPU 上。
优先将 MoE 参数和词嵌入计算放在 CPU 端以利用其更大的内存容量。其余参数(包括共享专家、注意模块中的投影和 MLA)存储在 GPU VRAM 中。由于每个 token 都会访问这些参数,因此将它们放置在 GPU 上可以最大限度地发挥高内存带宽的优势。如果使用 Q4_K_M 版本,此配置将导致大约 20.7 GB 的 VRAM 使用量和 136GB 的 DRAM 内存请求,即使在本地桌面上也是可行的。
- MLA 运算符(包含 128 个头,具有共享的压缩键值表示)的算术强度为 512。这使其成为最密集的运算符,尤其是在较小的推理批次大小期间。因此,它被分配给 GPU 以利用张量核心。
- DeepSeek-V2 中的每个转换器块包含 160 位混合专家 (MoE) 专家,占总参数的 96%。但是,MoE 路由器为每个 token 仅激活这 160 位专家中的 6 位。因此,此操作主要涉及批量通用矩阵向量乘法 (GEMV),可以由 CPU 高效处理。
参考
- 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
- 知乎:如何看待 DeepSeek 发布的 MoE 大模型 DeepSeek-V2







